
Regression
The idea behind regression is that when there is significant linear correlation, you can use a line to estimate the value of the dependent variable for certain values of the independent variable.The regression equation should only used
- When there is significant linear correlation. That is, when you reject the null hypothesis that rho=0 in a correlation hypothesis test.
- The value of the independent variable being used in the estimation is close to the original values. That is, you should not use a regression equation obtained using x's between 10 and 20 to estimate y when x is 200.
- The regression equation should not be used with different populations. That is, if x is the height of a male, and y is the weight of a male, then you shouldn't use the regression equation to estimate the weight of a female.
- The regression equation shouldn't be used to forecast values not from that time frame. If data is from the 1960's, it probably isn't valid in the 1990's.
Simple regression is used to examine the relationship between one dependent and one independent variable. After performing an analysis, the regression statistics can be used to predict the dependent variable when the independent variable is known. Regression goes beyond correlation by adding prediction capabilities.
People use regression on an intuitive level every day. In business, a well-dressed man is thought to be financially successful. A mother knows that more sugar in her children's diet results in higher energy levels. The ease of waking up in the morning often depends on how late you went to bed the night before. Quantitative regression adds precision by developing a mathematical formula that can be used for predictive purposes.
For example, a medical researcher might want to use body weight (independent variable) to predict the most appropriate dose for a new drug (dependent variable). The purpose of running the regression is to find a formula that fits the relationship between the two variables. Then you can use that formula to predict values for the dependent variable when only the independent variable is known. A doctor could prescribe the proper dose based on a person's body weight.
The regression line (known as the least squares line) is a plot of the expected value of the dependent variable for all values of the independent variable. Technically, it is the line that "minimizes the squared residuals". The regression line is the one that best fits the data on a scatterplot.
Using the regression equation, the dependent variable may be predicted from the independent variable. The slope of the regression line (b) is defined as the rise divided by the run. The y intercept (a) is the point on the y axis where the regression line would intercept the y axis. The slope and y intercept are incorporated into the regression equation. The intercept is usually called the constant, and the slope is referred to as the coefficient. Since the regression model is usually not a perfect predictor, there is also an error term in the equation.
In the regression equation, y is always the dependent variable and x is always the independent variable. Here are three equivalent ways to mathematically describe a linear regression model.
y = intercept + (slope  x) + error
x) + error
y = constant + (coefficientx) + error
y = a + bx + e
The significance of the slope of the regression line is determined from the t-statistic. It is the probability that the observed correlation coefficient occurred by chance if the true correlation is zero. Some researchers prefer to report the F-ratio instead of the t-statistic. The F-ratio is equal to the t-statistic squared.
The t-statistic for the significance of the slope is essentially a test to determine if the regression model (equation) is usable. If the slope is significantly different than zero, then we can use the regression model to predict the dependent variable for any value of the independent variable.
On the other hand, take an example where the slope is zero. It has no prediction ability because for every value of the independent variable, the prediction for the dependent variable would be the same. Knowing the value of the independent variable would not improve our ability to predict the dependent variable. Thus, if the slope is not significantly different than zero, don't use the model to make predictions.
The coefficient of determination (r-squared) is the square of the correlation coefficient. Its value may vary from zero to one. It has the advantage over the correlation coefficient in that it may be interpreted directly as the proportion of variance in the dependent variable that can be accounted for by the regression equation. For example, an r-squared value of .49 means that 49% of the variance in the dependent variable can be explained by the regression equation. The other 51% is unexplained.
The standard error of the estimate for regression measures the amount of variability in the points around the regression line. It is the standard deviation of the data points as they are distributed around the regression line. The standard error of the estimate can be used to develop confidence intervals around a prediction.
Example
A company wants to know if there is a significant relationship between its advertising expenditures and its sales volume. The independent variable is advertising budget and the dependent variable is sales volume. A lag time of one month will be used because sales are expected to lag behind actual advertising expenditures. Data was collected for a six month period. All figures are in thousands of dollars. Is there a significant relationship between advertising budget and sales volume?
| Indep. Var. | Depen. Var |
| 4.2 | 27.1 |
| 6.1 | 30.4 |
| 3.9 | 25.0 |
| 5.7 | 29.7 |
| 7.3 | 40.1 |
| 5.9 | 28.8 |
--------------------------------------------------
Model: y = 9.873 + (3.682x) + error
Standard error of the estimate = 2.637
t-test for the significance of the slope = 3.961
Degrees of freedom = 4
Two-tailed probability = .0149
r-squared = .807
Standard error of the estimate = 2.637
t-test for the significance of the slope = 3.961
Degrees of freedom = 4
Two-tailed probability = .0149
r-squared = .807
You might make a statement in a report like this: A simple linear regression was performed on six months of data to determine if there was a significant relationship between advertising expenditures and sales volume. The t-statistic for the slope was significant at the .05 critical alpha level, t(4)=3.96, p=.015. Thus, we reject the null hypothesis and conclude that there was a positive significant relationship between advertising expenditures and sales volume. Furthermore, 80.7% of the variability in sales volume could be explained by advertising expenditures.
Assuming that you've decided that you can have a regression equation because there is significant linear correlation between the two variables, the equation becomes:y' = ax + b or y' = a + bx (some books use y-hat instead of y-prime). The Bluman text uses the second formula, however, more people are familiar with the notion of y = mx + b, so I will use the first.
a is the slope of the regression line:
b is the y-intercept of the regression line:
The regression line is sometimes called the "line of best fit" or the "best fit line".
Since it "best fits" the data, it makes sense that the line passes through the means.
The regression equation is the line with slope a passing through the point
Another way to write the equation would be
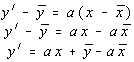
 apply just a little algebra, and we have the formulas for a and b that we would use (if we were stranded on a desert island without the TI-82) ...
apply just a little algebra, and we have the formulas for a and b that we would use (if we were stranded on a desert island without the TI-82) ...It also turns out that the slope of the regression line can be written as
 . Since the standard deviations can't be negative, the sign of the slope is determined by the sign of the correlation coefficient. This agrees with the statement made earlier that the slope of the regression line will have the same slope as the correlation coefficient.
. Since the standard deviations can't be negative, the sign of the slope is determined by the sign of the correlation coefficient. This agrees with the statement made earlier that the slope of the regression line will have the same slope as the correlation coefficient.Scatter Plots
- Enter the x values into L1 and the y variables into L2.
- Go to Stat Plot (2nd y=)
- Turn Plot 1 on
- Choose the type to be scatter plot (1st type)
- Set Xlist to L1
- Set Ylist to L2
- Set the Mark to any of the three choices
- Zoom to the Stat setting (#9)
Regression Lines
- Setup the scatter plot as instructed above
- Go into the Stats, Calc, Setup screen
- Setup the 2-Var Stats so that: Xlist = L1, Ylist = L2, Freq = 1
- Calculate the Linear Regression (ax+b) (#5)
- Go into the Plot screen.
- Position the cursor on the Y1 plot and hit CLEAR to erase it.
- While still in the Y1 data entry field, go to the VARS, STATS, EQ screen and choose option 7 which is the regression equation
- Hit GRAPH
Regression Lines, part 2
The above technique works, but it requires that you change the equation being graphed every time you change problems. It is possible to stick the regression equation "ax+b" into the Y1 plot and then it will automatically graph the correct regression equation each time.Do this once
- Setup the scatter plot as instructed above
- Go into the Plot screen.
- Position the cursor on the Y1 plot and hit CLEAR to erase it.
- Enter a*x+b into the function. The a and b can be found under the VARS, STATS, EQ screen
Do this for each graph
- Go into the Stats, Calc, Setup screen
- Setup the 2-Var Stats so that: Xlist = L1, Ylist = L2, Freq = 1
- Calculate the Linear Regression (ax+b) (#5)
- Hit the GRAPH key
Be sure to turn off the stats plots and/or the Y1 plot when you need to graph other data
.Standard Error of Estimate

The above equation is called the Standard Error of Estimate of y on x. It is important to note that this Standard Error of Estimate has properties analogous to those of standard deviation.Example:
- The regression line of y on x is given by the equation:
y = 35.82 + 0.476 x The following table depicts the actual values of y and the estimated values of y (denoted by yest).x 65 63 67 64 y 68 66 68 65 yest 66.76 65.81 67.71 66.28 y - yest 1.24 0.19 0.29 -1.28 
Correlation Coefficient
How well does your regression equation truly represent
your set of data?
One of the ways to determine the answer to this question is to
exam the correlation coefficient and the coefficient of determination.
your set of data?
One of the ways to determine the answer to this question is to
exam the correlation coefficient and the coefficient of determination.
 |
The correlation coefficient, r, and
the coefficient of determination, r 2 , will appear on the screen that shows the regression equation information (be sure the Diagnostics are turned on --- 2nd Catalog (above 0), arrow down to DiagnosticOn, press ENTER twice.) |
In addition to appearing with the regression information, the values r and r 2 can be found under VARS, #5 Statistics → EQ #7 r and #8 r 2 .
|
| Correlation Coefficient, r : |
the direction of a linear relationship between two variables. The linear correlation
coefficient is sometimes referred to as the Pearson product moment correlation coefficient in
honor of its developer Karl Pearson.
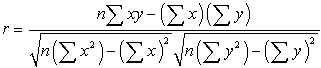
where n is the number of pairs of data.
(Aren't you glad you have a graphing calculator that computes this formula?)
linear correlations and negative linear correlations, respectively.
to +1. An r value of exactly +1 indicates a perfect positive fit. Positive values
indicate a relationship between x and y variables such that as values for x increases,
values for y also increase.
to -1. An r value of exactly -1 indicates a perfect negative fit. Negative values
indicate a relationship between x and y such that as values for x increase, values
for y decrease.
close to 0. A value near zero means that there is a random, nonlinear relationship
between the two variables
employed.
straight line. If r = +1, the slope of this line is positive. If r = -1, the slope of this
line is negative.
less than 0.5 is generally described as weak. These values can vary based upon the
"type" of data being examined. A study utilizing scientific data may require a stronger
correlation than a study using social science data.
| Coefficient of Determination, r 2 or R2 : |
the variance (fluctuation) of one variable that is predictable from the other variable.
It is a measure that allows us to determine how certain one can be in making
predictions from a certain model/graph.
variation.
of the linear association between x and y.
to the line of best fit. For example, if r = 0.922, then r 2 = 0.850, which means that
85% of the total variation in y can be explained by the linear relationship between x
and y (as described by the regression equation). The other 15% of the total variation
in y remains unexplained.
represents the data. If the regression line passes exactly through every point on the
scatter plot, it would be able to explain all of the variation. The further the line is
away from the points, the less it is able to explain.


